Amazon Review Classification and Clustering with ML

Binary Classification: Good vs Bad Reviews:
What I Did
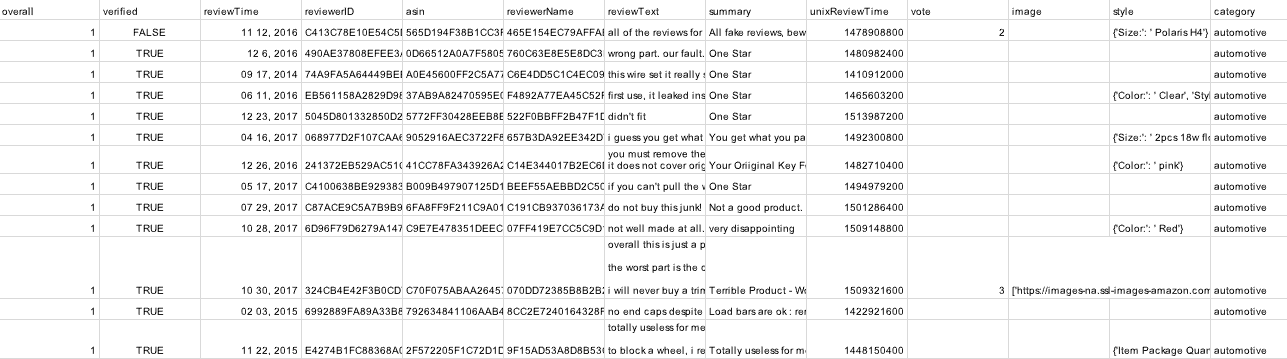
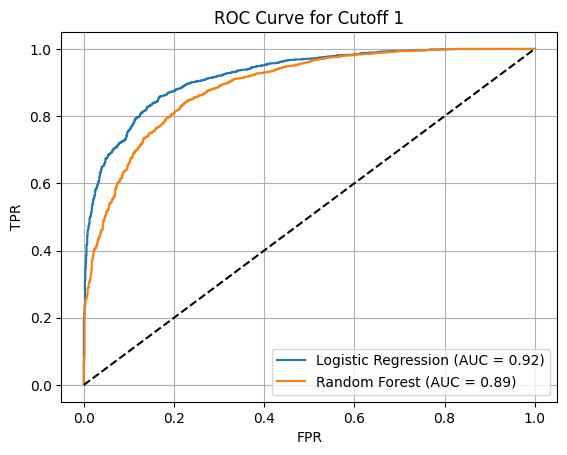
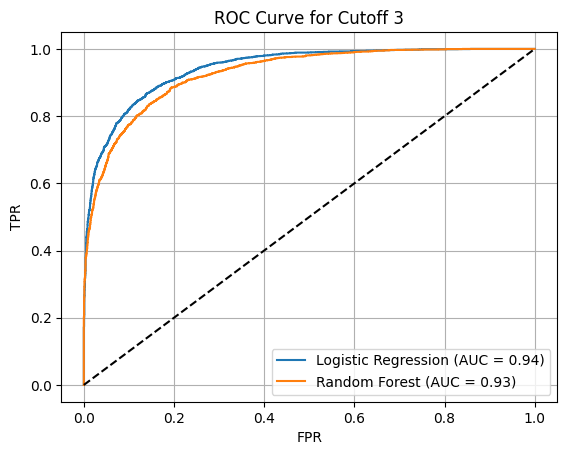
I framed sentiment prediction as a binary classification problem, labeling reviews as good or bad based on multiple rating cutoffs (1, 2, 3, and 4). This allowed me to study how model performance changes as the definition of “positive sentiment” becomes stricter or more lenient.
For each cutoff, I trained and compared three classifiers:
Logistic Regression
Linear SVM
Random Forest
All models were tuned using 5-fold cross-validation and evaluated with these standard classification metrics:
ROC curves and AUC
Confusion matrices
Accuracy and macro F1 score
The ROC plots show how well each model separates positive and negative reviews under different cutoff definitions.
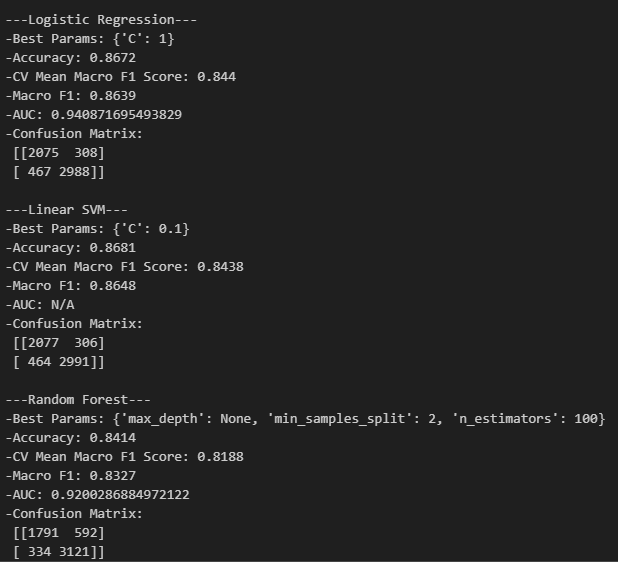
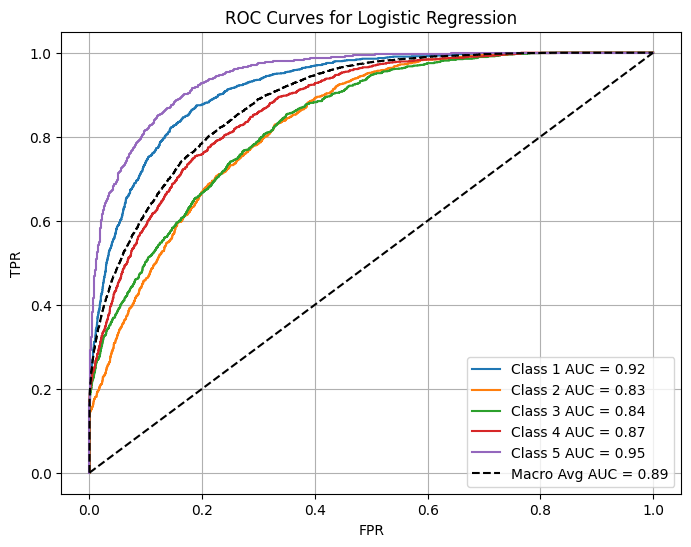
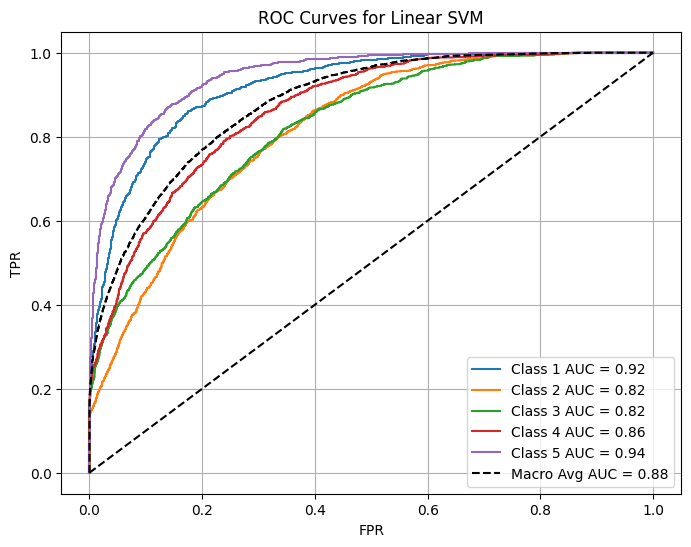
Multiclass Classification: Predicting 1–5 Star Ratings:
What I Did
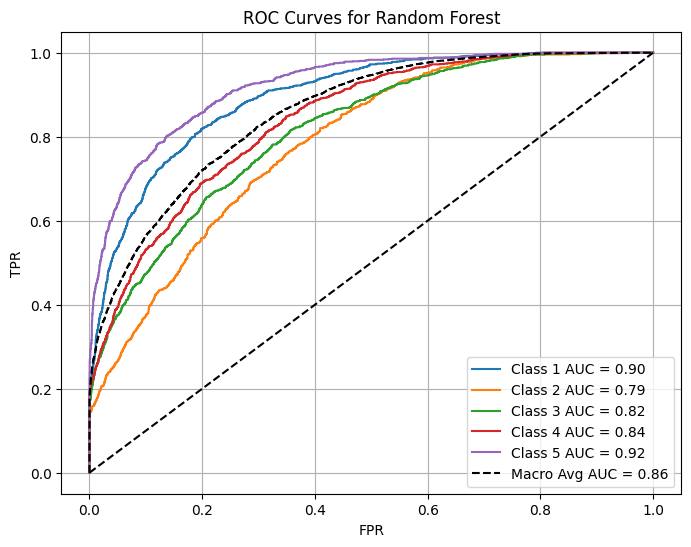
I extended the binary setup to a five-class classification problem, predicting exact star ratings (1–5) directly from review text.
Using the same feature pipeline, I trained:
Multinomial Logistic Regression
Multiclass SVM (one-vs-rest)
Random Forest
All models were again tuned with 5-fold cross-validation to ensure fair comparison.
For each classifier, I reported:
Multiclass confusion matrices
One-vs-rest ROC curves and per-class AUC
Macro F1 score and accuracy
The ROC plots illustrate how well each class (rating level) is separated from the others.
Clustering: Discovering Structure Without Labels:
What I Did
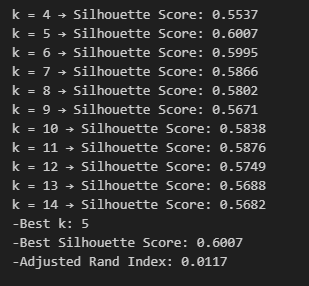
To explore structure beyond labeled sentiment, I applied k-means clustering to vectorized review text, clustering reviews by product category without using labels during training.
I experimented with different values of k and evaluated clustering quality using:
Silhouette score (cluster separation)
Adjusted Rand Index (alignment with known categories)
The results show:
Silhouette scores across different cluster counts
The selected value of k that maximized cluster quality
How well unsupervised clusters aligned with known product labels
These metrics quantify how much structure exists in review text without supervision.
An applied machine learning project analyzing large-scale product reviews to classify sentiment and uncover structure in consumer feedback using supervised and unsupervised learning methods.
Overview:
This project applies machine learning techniques to real-world product review data to understand how textual feedback reflects user sentiment and how reviews naturally cluster based on content and tone.
Using a large corpus of Amazon product reviews, the project explores both supervised learning (sentiment classification) and unsupervised learning (clustering), emphasizing careful feature design, model evaluation, and interpretability rather than black-box performance alone.
The dataset consists of labeled product reviews containing:
Review text
Star ratings
Key preprocessing steps included:
Text cleaning and normalization
Vectorization using bag-of-words / TF-IDF representations
Dimensionality considerations for scalability and generalization
Special care was taken to avoid data leakage and to ensure fair train/test splits.